
Text annotation enhances NLU systems by improving contextual understanding, intent recognition and sentiment analysis. Techniques like entity recognition and stringent quality checks ensure accuracy, boost AI model performance, reduce costs, and enable real-world applications like virtual assistants, sentiment analysis, and data validation.
Natural Language Understanding (NLU) is changing how machines interpret human language, driving advancements in AI-powered systems across industries. At the core of this transformation lies text annotation in NLU, a critical process that provides labeled data to train models for contextual understanding and semantic accuracy.
From text labeling for NLU models to advanced techniques like semantic segmentation, annotation enables models to grasp nuances in language, helping to execute tasks such as sentiment analysis, intent recognition, and real-time decision-making more effectively. This article explores how NLU, driven by AI-powered text annotation, is increasing the potential of language-based AI applications in real life.
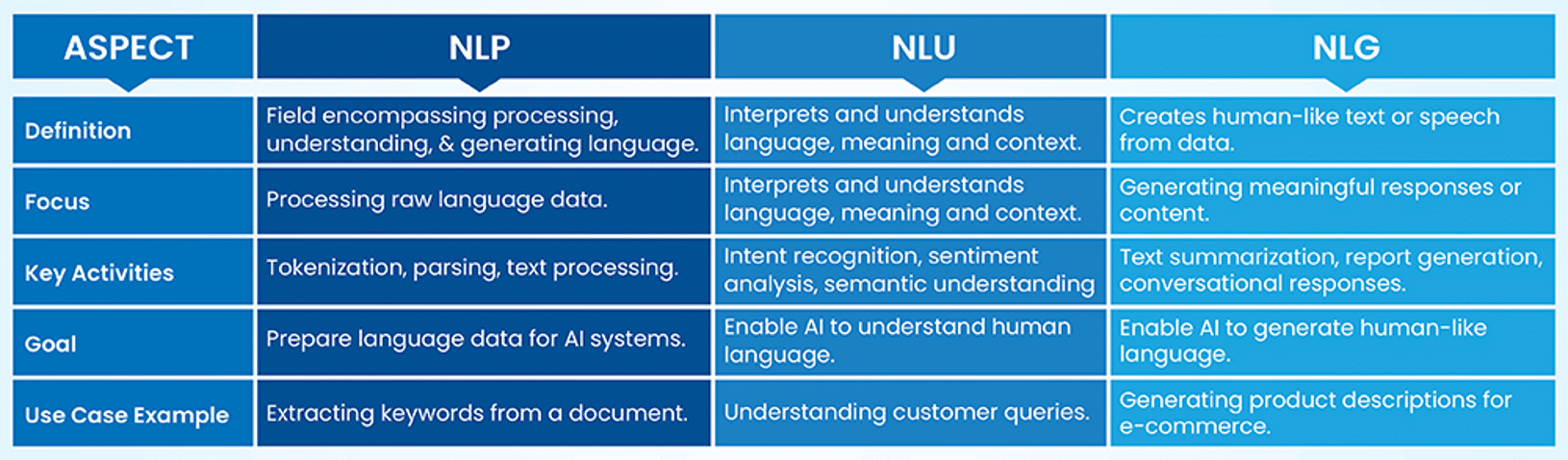
Understanding NLU and How it Differs from NLP and NLG

Natural Language Understanding (NLU) is a specialized branch of AI that goes beyond processing language. It enables machines to truly comprehend, interpret and derive meaning from human communication. Unlike general natural language processing (NLP), which focuses on processing and manipulating text, NLU probes deeper into understanding context, intent and semantics. It powers applications like chatbots, sentiment analysis, and virtual assistants by interpreting nuanced user queries, such as distinguishing ‘book a flight’ from ‘cancel my booking.’
While NLU focuses on comprehension, natural language generation (NLG) is about creating human-like responses, completing the cycle of AI language interaction. Together, NLP, NLU and NLG form the backbone of intelligent language systems. Whether extracting entities, resolving ambiguity, or analyzing sentiment, NLU plays a critical role in making AI-powered tools like virtual assistants more contextually aware and precise, elevating how machines interact with human language.
NLU vs. NLP vs. NLG: Key Differences Explained
How Does Text Annotation Enhance Contextual Understanding in NLU Models?
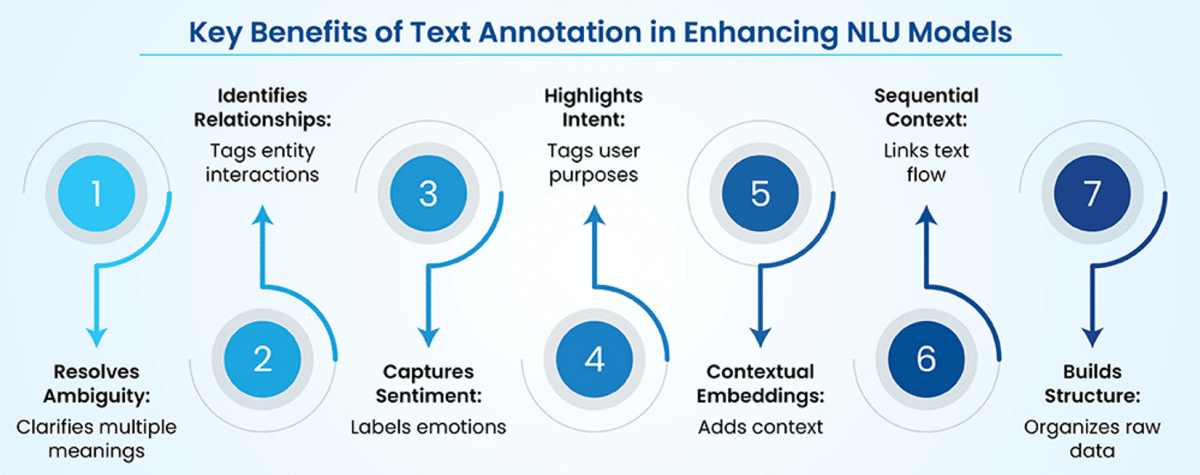
Text annotation plays a critical role in enabling NLU models to comprehend language within its context, address ambiguities, and ensuring nuanced understanding.
Here’s how it enhances contextual understanding:
· Resolves ambiguity – Many words and phrases have multiple meanings depending on the context. Text annotation resolves ambiguity by assigning context-specific labels to words or phrases with multiple meanings. For instance, annotating ‘bank’ in ‘riverbank’ as a geographical feature and ‘deposit money at the bank’ as a financial institution ensures precise understanding.
· Identifies relationships between entities – Language often involves complex relationships between different entities. Text annotation identifies complex relationships by labeling interactions like ‘owns’ or ‘acquired.’ For example, annotating Google’ as the acquirer and YouTube’ as the acquired entity in ‘Google acquired YouTube in 2006’ clarifies their relationship.
· Captures context-dependent sentiment – Sentiment often depends on the specific context of a sentence or phrase. Text annotation captures nuanced emotions by labeling sentiments within specific contexts. For instance, in ‘The phone is great, but the battery life is poor,’ annotations mark ‘phone’ as positive and ‘battery life’ as negative, ensuring accurate sentiment analysis.
· Highlights intent and purpose – User input can have various intents that need to be differentiated. Annotating intent labels helps distinguish user purposes, such as ‘query’ or ‘request.’ For example, labeling ‘I’d like to know my order status’ as a ‘tracking request’ enables the system to respond with appropriate information.
· Enables contextual word embeddings – Words derive meaning from the sentences they appear in. Text annotation enriches word embeddings by adding contextual labels. For instance, annotating ‘bat’ in ‘swing the bat’ as sports equipment ensures models distinguish it from the animal in different contexts.
· Provides training data for sequential context – Conversations and text sequences require understanding past context to interpret the current input. Sequential annotation ensures models understand evolving contexts. For example, labeling ‘What about tomorrow?’ as referencing a prior meeting lets the model maintain conversational continuity in understanding past and current inputs.
· Builds structured data from unstructured text – Raw text data lacks structure, making it hard for models to derive meaning. Annotation converts raw text into structured data by tagging key elements like entities and dates. For example, annotating ‘John booked a flight to Paris for next Monday’ with labels for ‘person,’ ‘destination,’ and ‘date’ clarifies the action and its components.
Top 7 Text Annotation Techniques for NLU Models

Text annotation techniques form the foundation of natural language understanding (NLU) by enabling models to process and interpret human language with precision. These techniques, when applied effectively, power various real-world applications of NLU across industries.
1. Entity recognition
This technique identifies and labels entities like names, dates, locations, and organizations, enabling systems to extract key information for tasks, such as information retrieval and query resolution.
Identifies entities like names, dates and locations; Example: Labels “Apple” as a company and “2024” as a date in “Apple launched a product in 2024.”
2. Intent annotation
Intent labeling assigns specific purposes to text, such as booking, inquiries or complaints, which helps models understand user goals and respond appropriately.
Tags user intents like booking, inquiry or request; Example: Marks “Can I book a flight?” as a “booking intent.”
3. Sentiment annotation
Sentiment tagging classifies text as positive, negative or neutral, enabling systems to analyze emotional tones and support applications like feedback analysis and brand monitoring.
Classifies text as positive, negative or neutral. Example: Tags “The service was great” as positive sentiment.
4. Semantic annotation
This technique links entities and phrases to their relationships, providing deeper contextual insights for applications such as knowledge graph creation and advanced search systems.
Links entities and their relationships; Example: Connects “Tesla” to “manufactures” in “Tesla manufactures electric cars.”
5. Part-of-Speech (POS) tagging
Labels grammatical roles like nouns, verbs and adjectives, improving syntactic analysis and supporting text parsing and language translation tasks.
Labels words as nouns, verbs, adjectives, etc.; Example: Tags “cat” as a noun and “sleeps” as a verb in “The cat sleeps.”
6. Co-reference resolution annotation
Resolves pronouns and other references to the same entity within the text, ensuring models maintain consistency and context in conversations and documents.
Resolves references like pronouns; Example: Links “he” to “John” in “John said he was tired.”
7. Text classification
Categorizes text into predefined groups, such as topics or genres, streamlining processes like content organization, and recommendation systems.
Groups text into categories like news or sports; Example: Categorizes “Local Team Wins Championship” as “sports.”
By integrating these annotation techniques, NLU systems excel in diverse real-world applications. Text annotation techniques also help address complex challenges in data classification; for instance, employing a two-step quality check and appending missing information not only ensured accurate classification but also enhanced AI algorithm performance, increasing customer acquisition and cutting project costs by 50%.
Challenges in Text Annotation for NLU and Solutions
Text annotation for natural language understanding (NLU) faces challenges like ambiguity and subjectivity, where multiple interpretations of text cause inconsistencies. Experts play a critical role in creating clear annotation guidelines and conducting cross-validation to ensure accuracy.
Scalability issues arise from labour-intensive manual processes, but AI-assisted tools, combined with expert oversight, improve efficiency. Human errors and fatigue impact quality, which can be mitigated with peer reviews and automated quality checks led by experienced annotators.
Domain-specific fields, such as healthcare, require specialized knowledge, making expert training essential. Data privacy risks demand anonymization and compliance with regulations, while linguistic and cultural variations call for region-specific annotators and expert-designed localized guidelines to ensure consistency and relevance.
Conclusion
Natural Language Understanding (NLU) is transforming how machines interpret human language, enabling smarter and more context-aware AI applications. Central to this success is text annotation, which provides the structured, labeled data that NLU models need to grasp meaning, context and intent with precision.
From enhancing sentiment analysis to powering virtual assistants, text annotation elevates the potential of NLU across industries. While challenges like scalability and ambiguity persist, advancements in AI-assisted tools and expert-driven annotation practices are addressing these hurdles. As NLU continues to evolve, the synergy between annotation techniques and expert insights will unlock the new heights of language-based AI innovation.